
In the evolving world of machine learning, developing a high-performing model is just half the battle. Equally important is how we evaluate that model to ensure it performs well on unseen data. One of the most effective strategies for robust evaluation is cross-validation. Whether you’re a beginner just getting started or someone pursuing a Data Science Course, understanding cross-validation is essential for building reliable, generalisable models. This blog will explore various cross-validation techniques, their use cases, benefits, limitations, and best practices.
What is Cross-Validation?
Cross-validation is a statistical method for estimating a machine learning model’s skill. It divides the data into multiple subsets (or folds), trains the model on some of these folds, and tests it on the remaining ones. This ensures that every observation from the original dataset has a chance of appearing in both the training and test sets.
The primary goal of cross-validation is to detect overfitting and ensure that the model generalises well to new, unseen data. Unlike a single train-test split that might be subject to selection bias, cross-validation gives a more accurate picture of a model’s performance.
Why Cross-Validation is Crucial?
- Reduces Overfitting: It ensures the model is not just memorising the data but learning patterns that generalise.
- Improves Generalisation: Testing the model on different subsets provides a better approximation of real-world performance.
- Model Comparison: It helps in selecting the best-performing algorithm among multiple models.
- Hyperparameter Tuning: Many optimisation algorithms, like Grid Search and Random Search, rely on cross-validation to find optimal parameters.
Common Cross-Validation Techniques
- Holdout Method
- Description: The dataset is randomly split into training and testing sets (commonly 70:30 or 80:20).
- Use Case: Suitable for large datasets where training and testing on subsets still offer good representation.
- Limitation: The evaluation may vary significantly based on how the data is split.
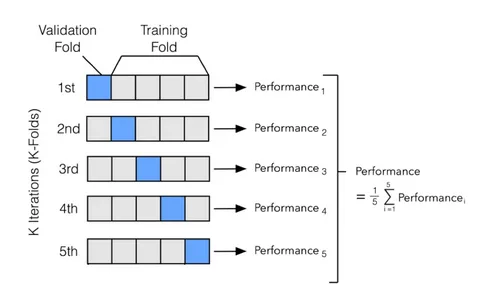
- K-Fold Cross-Validation
- Description: The data is divided into k equal parts. The model is trained on k-1 folds and tested on the remaining fold. This process is repeated k times.
- Use Case: The most widely used technique for general model evaluation.
- Advantages:
- Each data point is used for both training and testing.
- More reliable than the holdout method.
- Limitation: Computationally intensive for large datasets.
- Stratified K-Fold Cross-Validation
- Description: Similar to K-Fold, but maintains the percentage of samples for each class label across folds.
- Use Case: Ideal for imbalanced classification problems.
- Advantages:
- Ensures balanced distribution of target classes.
- Improves performance consistency.
- Limitation: Slightly more complex implementation.
- Leave-One-Out Cross-Validation (LOOCV)
- Description: Each fold consists of a single observation. The model is trained on all other observations.
- Use Case: Suitable for small datasets.
- Advantages:
- Maximises training data.
- Very accurate for small datasets.
- Limitations:
- Very slow for large datasets.
- High variance in test results.
- Leave-P-Out Cross-Validation
- Description: Similar to LOOCV, but leaves out p data points in each iteration.
- Use Case: Rarely used due to its computational intensity.
- Limitation: Not practical for large values of p or big datasets.
- Time Series Cross-Validation (Rolling or Expanding Window)
- Description: Designed for time-dependent data, the model is trained on past data and tested on future data.
- Use Case: Time series forecasting, stock market predictions, etc.
- Advantages:
- Respects the temporal structure of the data.
- Avoids leakage of future data.
- Limitation: Not applicable to randomly sampled datasets.
Best Practices for Using Cross-Validation
- Choose the Right Technique: Pick the cross-validation strategy based on data size, balance, and time-dependency.
- Stratify When Needed: Use stratified techniques for classification problems to preserve class distribution.
- Be Cautious with Time Series: Avoid random splits in time series data to maintain temporal integrity.
- Combine with Hyperparameter Tuning: Use techniques like GridSearchCV or RandomizedSearchCV, which implement internal cross-validation.
- Monitor Performance Metrics: Depending on the problem, evaluate models using mean accuracy, precision, recall, F1-score, or RMSE.
Real-World Applications
- Healthcare: Predicting disease risk using patient data where reliable evaluation is critical.
- Finance: Building credit scoring models or fraud detection algorithms.
- Retail: Customer segmentation and product recommendation systems.
- Manufacturing: Predictive maintenance systems that rely on time-series cross-validation.
Cross-validation is a safety net, preventing poor decision-making based on misleading accuracy scores. In many regulated industries like healthcare and finance, models are not accepted unless thoroughly validated using robust methods like cross-validation.
Pros and Cons Summary
| Technique | Pros | Cons |
| Holdout | Simple and fast | High variance due to random split |
| K-Fold | Reliable performance estimation | Time-consuming for large values of k |
| Stratified K-Fold | Balanced class representation | Slightly complex |
| Leave-One-Out (LOOCV) | Uses nearly all data for training | Computationally expensive |
| Leave-P-Out | Accurate for very small datasets | Practically infeasible for large datasets |
| Time Series CV | Respects time order | Not suited for random data |
Conclusion
Cross-validation is more than just a tool for model validation—it’s a cornerstone of trustworthy machine learning. When applied correctly, it enhances a model’s credibility, ensures fair evaluation, and leads to better decision-making. Understanding and implementing the right cross-validation strategy is essential for anyone aiming to excel in the data science domain.
If you’re aspiring to become a professional data scientist and master techniques like cross-validation, enrolling in a data scientist course in Hyderabad can provide the hands-on experience and expert guidance needed to thrive in the field. Whether it’s model selection, performance evaluation, or real-time project work, such a course equips you with the skills required to build models that are not just accurate but also reliable.
ExcelR – Data Science, Data Analytics and Business Analyst Course Training in Hyderabad
Address: Cyber Towers, PHASE-2, 5th Floor, Quadrant-2, HITEC City, Hyderabad, Telangana 500081
Phone: 096321 56744